파이썬을 이용해 채용사이트에서 내가 원하는 wording의 공고문을 가져오는 스크립트를 작성함
우선 크롬에서 개발자 도구를 이용해 내가 가져오기 위한 사이트에 접속을 해봄
이번에는 잡코리아에서 채용공고를 가져와 볼까 함
https://www.jobkorea.co.kr/ URL을 입력 하면, 다들 아는 것 처럼 잡코리아에 접속 되고 아쉽게도 팝업 창이 딱 떠오름
팝업을 종료하는 방법은 여러가지가 있지만, 여기에서는 beautifulsoup4를 이용해 html을 파싱 함

위에 캡쳐 화면 처럼 자세히 보면 div 태그에 class를 modal로 사용중인것을 볼 수 있음. 대부분 팝업에 class modal 효과를 주기 위해 사용한 것으로 보이기때문에,
modals = soup.find_all(class_="modal")
변수를 사용해 모달이 있는지 먼저 확인 하려고 함
만약에 모달이 없는 경우에는 다음 검색 동작을 진행 하면 되고, 이 부분에 대한 로직을 def 로 정의 함
def close_modals(driver):
"""모달 팝업을 감지하고 닫음"""
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
modals = soup.find_all(class_="modal")
if modals:
print(f"총 {len(modals)}개의 모달이 발견되었습니다.")
selenium_modals = driver.find_elements(By.CLASS_NAME, "modal")
if selenium_modals:
for modal in selenium_modals:
try:
close_btn = modal.find_element(By.CLASS_NAME, "btnClosePop")
close_btn.click()
print("모달을 닫았습니다.")
time.sleep(1)
except:
print("닫기 버튼을 찾지 못했습니다.")다음은 검색창에서 내가 원하는 채용 공고 워딩을 검색 할 차례다
사실 앞에 부분 보다 쉽기때문에 find_element(By.****) 을 이용해 검색어를 input box에 입력 하고 클릭 까지 하는 로직을 정의 함
def search_keyword(driver, word):
"""검색어 입력 후 검색 실행"""
try:
smkey_div = driver.find_element(By.CLASS_NAME, "smKey")
text_input = smkey_div.find_element(By.CSS_SELECTOR, 'input[type="text"]')
text_input.click()
text_input.send_keys(word)
print(f"'{word}' 입력 완료")
time.sleep(1)
submit_button = smkey_div.find_element(By.CSS_SELECTOR, 'input[type="submit"]')
submit_button.click()
print("검색 버튼 클릭 완료")
except Exception as e:
print("오류 발생:", e)
time.sleep(5)이렇게 까지 정의 하면, 쉽게 검색 내용까지 도달 할 수 있음
다음 단계는 실제로 내가 긁어오고자 하는 정보들을 찾아야 함
앞서 사용한 beautifulsoup4를 사용하기에는 정보가 너무 많고 불분명 하기 때문에 특정 class나 id 값이 unique 한지 확인해 보고 그걸 사용하는게 더 좋다는 생각으로 보임
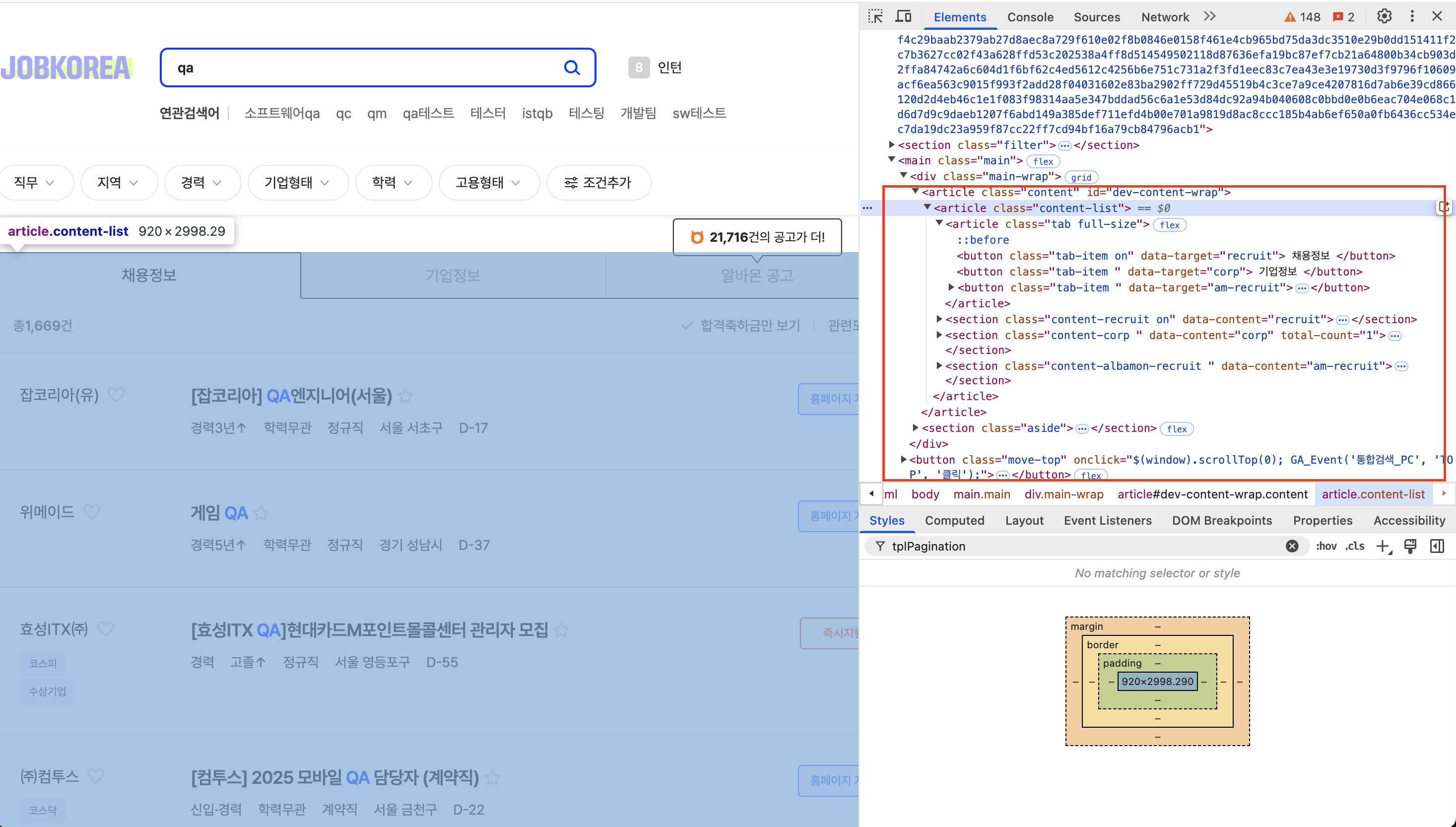
위에 이미지를 보면, article 태그에 content를 사용하는것이 나타남
각 정보들을 리스트 형태로 나타내 주고 있기 때문에 이것들을 가공해서 가지고 있는 속성 값을 추출 하는것이 좋을것으로 생각이 됨
아래 처럼 어떤 부분을 찾을지 선언 하고,
content_list = driver.find_element(By.CLASS_NAME, "content list")
list_items = content_list.find_elements(By.CLASS_NAME, "list-item")
아래 코드와 같이 내가 찾을 부분의 태그 속성값을 찾는 로직을 만들어 정의 함
def extract_list_items(driver):
"""content-list 안의 list-item을 찾아 데이터 추출"""
items_data = []
try:
content_list = driver.find_element(By.CLASS_NAME, "content-list")
list_items = content_list.find_elements(By.CLASS_NAME, "list-item")
if list_items:
print(f"총 {len(list_items)}개의 list-item 발견!")
for idx, item in enumerate(list_items, start=1):
data_gavirturl = item.get_attribute("data-gavirturl")
data_gainfo = item.get_attribute("data-gainfo")
if data_gavirturl or data_gainfo:
item_info = {
"index": idx,
"data_gavirturl": data_gavirturl,
"data_gainfo": data_gainfo
}
items_data.append(item_info)
print(f"{idx}.", end=" ")
if data_gavirturl:
print(f"data-gavirturl: {data_gavirturl}", end=" ")
if data_gainfo:
print(f"data-gainfo: {data_gainfo}")
print("\n")
else:
print("list-item 요소를 찾지 못했습니다.")
except Exception as e:
print("list-item 추출 중 오류 발생:", e)
return items_data정의된 함수들을 실행 하면, 내가 원하는 키워드로 검색이 가능 하고 찾고자 하는 내용까지 출력이 가능함
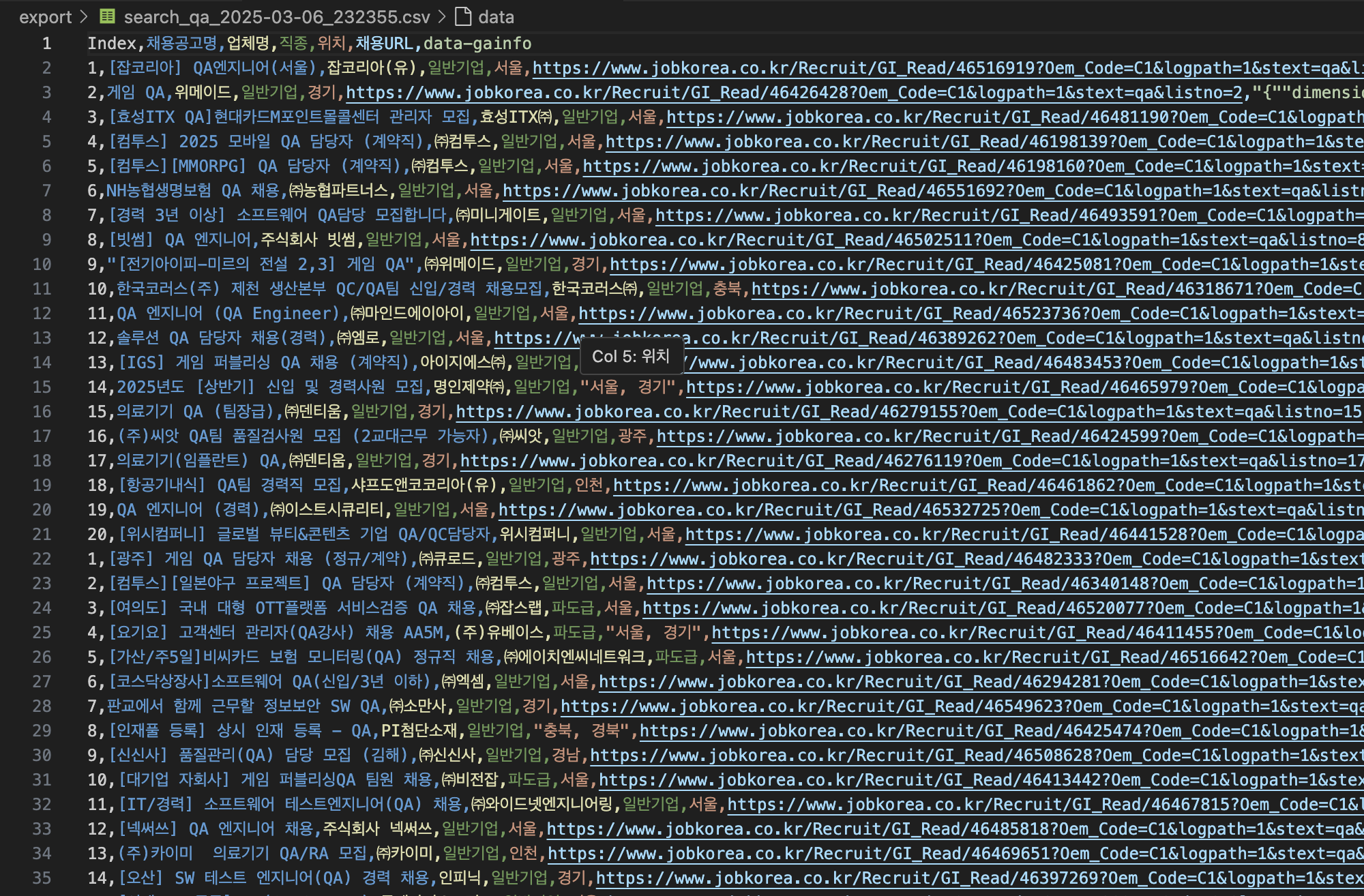
그밖에도 페이지를 클릭해 다음 화면을 가지고 오고 이 화면들을 콘솔로만 출력하는게 아니라
txt, csv등 문서로도 저장 할 수 있음
개발쪽으로 직무 전환중인데 맘대로도 안되고... 답답해서 오랜만에 포스팅도 해볼 겸 만들어봤음
자세한 내용들은 아래 동영상이랑 csv를 참고 (?) 하면 쉽게 커스터마이징이 가능 할거 같고,
그래도 잘 모르겠으면 github에서 그냥 스크립트를 긁어서 사용하면 될듯함 ㅎㅎ
'QA Engineering > Tool & Automation' 카테고리의 다른 글
| Faucet에서 자동으로 자금을 전송 받아보자 (1) | 2024.02.01 |
|---|---|
| 셀레니움 웹 페이지 로딩이 너무 길어 질때 (0) | 2023.11.18 |
| 검색 쿼리 encode, url 파싱 (1) | 2023.11.03 |
| AWS cron 스케쥴링 설정 (0) | 2023.09.14 |
| QARK(Quick Android Review Kit) (0) | 2023.09.08 |